


En 2017, el periódico «La atención es todo lo que necesitas«Google cambió la base técnica de la generación de idiomas: el Transformadores Permitieron procesar secuencias largas en modelos paralelos y escalar a tamaños que anteriormente eran inviables. Esa ruta de escalada ha impulsado arquitecturas como GPT y Bert y se ha convertido en auto -actuación en La pieza central de IA generativa Contemporáneo.
Pero este nuevo enfoque fue acompañado por los crecientes costos en la memoria y la energía cuando el contexto se alarga, una limitación que ha motivado la investigación para desarrollar alternativas. SpikingBrain-1.0 tiene como objetivo romper los moldes.
De la «atención es todo lo que necesitas» para el cerebro: el nuevo compromiso de romper los límites en el
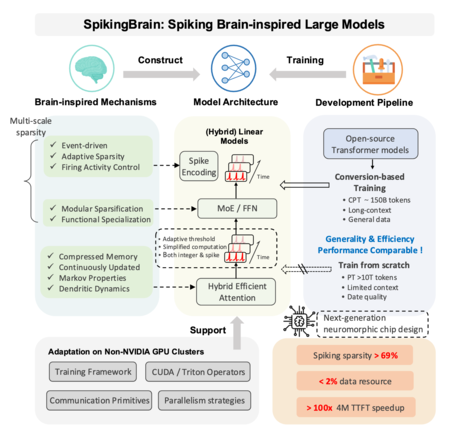
Un equipo del Instituto de Automatización de la Academia China de Ciencias Acaba de presentar spikingbrain-1.0. Estamos hablando de una familia de modelos puntiagudos destinados a reducir los datos y el cálculo necesarios para las tareas con contextos muy largos. Los expertos proponen dos enfoques: SpikingBrain-7b, de arquitectura lineal centrada en la eficiencia y SpikingBrain-76b, que combina atención lineal con la mezcla de expertos (MOE) mecanismos de mayor capacidad.
Los autores detallan que gran parte del desarrollo y las pruebas se llevaron a cabo en grupos de GPU Metax C550, con bibliotecas y operadores diseñados específicamente para esa plataforma. Esto hace que el proyecto no solo sea un avance prometedor a nivel de software, sino también una demostración de Capacidades de hardware propias. Un aspecto especialmente relevante si el esfuerzo de China se tiene en cuenta para reducir su dependencia de Nvidia, una estrategia que ya hemos visto con Deepseek 3.1.
SpikingBrain-1.0 se inspira directamente en cómo funciona nuestro cerebro. En lugar de tener neuronas que siempre se «queman» calculando números, usa neuronas puntiagudas: unidades que acumulan señales hasta que exceden un umbral y desencadenan un pico (pico). Entre el pico y el pico no hacen nada, lo que ahorra operaciones y, en teoría, energía. La clave es que no solo importa cuántos picos hay, sino cuando ocurren: el momento exacto y el orden de estos picos llevan información, como en el cerebro.
Para que este diseño funcione con el ecosistema actual, el equipo desarrolló métodos que convierten los bloques de auto -actuación tradicionales en versiones lineales, más fáciles de integrar en su sistema puntiagudo y crearon una especie de «tiempo virtual» que simula procesos temporales sin detener el rendimiento en GPU. Además, la versión SpikingBrain-76B incluye la mezcla de expertos (MOE), un sistema que «despierta» solo ciertos submodelos cuando necesitamos, que también hemos visto en GPT-4O y GPT-5.
Los autores sugieren aplicaciones donde la longitud del contexto es decisiva: análisis de grandes archivos legales, registros médicos completos, secuenciación de ADN y conjuntos de datos experimentales masivos en física de alta energía, entre otros. Ese encaje parece razonado en el documento: si la arquitectura mantiene la eficiencia en contextos de millones de tokens, reduciría los costos y las posibilidades abiertas en los dominios hoy limitados por el acceso a una infraestructura informática muy costosa. Pero la validación en entornos reales está pendiente fuera del laboratorio.
El equipo El código de 7,000 millones de parámetros se ha lanzado en Github junto a un informe técnico detallado. También ofrece una interfaz web similar a ChatGPT para interactuar con el modeloque según los autores se implementan completamente en hardware nacional. Acceso, sin embargo, se limita al chinolo que complica su uso fuera de ese ecosistema. La propuesta es ambiciosa, pero su verdadero alcance dependerá de la comunidad para reproducir los resultados y hacer comparaciones en entornos homogéneos que evalúan la precisión, las latencias y el consumo de energía en condiciones reales.
Imágenes | con Géminis 2.5 | Abodi vesakaran
En | Operai cree que al descubrir por qué el IAS alucina: no saben cómo decir «No sé»


{kind=link}